 Adam Segoli Schubert
Adam Segoli Schubert
Dori 曾在之前的博客《如何高效创建 C++ 并行构建?》中,提到了 Chandler Carruth 在 CPPCon 2019 中一个很棒的演讲,《没有零成本的抽象》。正如Dori 和 Chandler 强调,我们可以从三个主要标准来衡量编码效率及其构建、测试和发布系统:运行时间、构建时间,当然还有人工时间。
如果你还没看 Chandler 的演讲,建议大家可以抽时间了解一下。他在演讲中展示了一个 C++11 移动语义的有趣测试用例。如果你想了解更多移动语义的相关内容,链接中的内容会很有帮助。不过,如果对你来说,这个内容太过简单,你可以将它推荐给身边初学的朋友。?
构建时间和运行时间

运行时间的概念简单明了。我们都知道这是在编写计算机程序或算法的时候需要考虑的问题。构建时间也很重要,甚至极为关键。但大部分人只有在首次接触大规模代码库时才意识到这一点。等待构建完成纯粹是浪费时间。试想一下,6 名工程师一起等待一个 10 分钟的构建,相当于浪费了 60 分钟的工程师时间。在这期间,他们改进、分析代码的能力完全被搁置,或者说被限制。另外,这段浪费的等待时间还要乘以代码在一天、一周、一个月内的构建次数……这浪费了多少人类时间!接下来,我们将用一个新的方案解决刚刚说的等待问题,让你在行业竞赛中始终保持领先。
当然,构建和运行时间之间需要权衡。要减少运行时间,我们需要使用编译器优化,以生成更高效的代码。且现在的编译器在代码优化方面做得很好,但这当然要付出代价——构建时间增加。
用于代码优化的 gcc 编译命令如下(点击链接,查看 Clang 优化):
gcc -O2 -flto (flto 用于Link Time Optimization优化,我们将在后面讨论)
请注意,根据 GNU 用户手册,-Og(不是 -O2)是标准编辑-编译-调试周期的推荐优化级别。这个优化级别设置很合理,同时可以保证编译速度和良好的调试功能。-O0(默认设置)可以缩短编译时间,并且帮助代码调试,因为编译的二进制文件“更接近”源代码流和逻辑。然而,根据 GNU 的说法,-Og 将是一个更好的选择,因为它的调试信息比 -O0 更充分。优化标志:-O1、-O2、-O3(完整的优化说明,请参阅链接),优化功能按顺序递增。如 -O3 可执行所有的 -O2 优化,另外还会有一些附加优化功能。一般情况下,优化增加,意味着构建时间也会增加。在需要权衡运行时间/构建时间时,许多人觉得使用 -O3 获得的性能不足以抵消其耗费的构建时间,所以仍然选择 -O2。另外一个冷门的 Ofast 选项,也是因为需要减少构建时间。
在性能权衡的问题中,也不得不提到运行时间与代码大小的选择。-Os 优化了代码大小,它支持大部分的-O2 优化,同时还避免了代码增大的问题。
链接时间优化
The -flto[=n] option runs the standard link-time optimizer. To be used, -flto and optimization options should be specified in both compile time and during the final link. Object files generated with LTO support are larger than regular object files. This allows further optimizations after object codes have already been created.
-flto[=n] 选项可运行标准链接时间优化器。-flto 和优化选项需要在编译时和最终链接期间进行设定,才能使用。使用 LTO 功能生成的对象文件比常规文件大,不过我们可以在后面进一步优化。
使用 -flto=jobserver,在 GNU make jobserver 模式下(详见下文)确定所有可执行的并行作业总数。当调用 GCC 的 Makefile 已经在进行并行执行时,这个功能非常有用。在父 Makefile 的命令前加一个“+”,即可使其生效。即使没有设定选项值,GCC 也会自动检测正在运行的 GNU make jobserver。如果可以,用 -flto=auto 来运行 GNU make jobserver,不然的话就需要返回到自动检测系统,查看存在的 CPU 线程数。
更多信息和相关限制,请参阅链接。
加速构建——挖掘并行潜能
GNU Make 能够并行运行多种命令(请参阅并行执行),并限制并行作业的总数,即使是在对 Make 的递归调用命令中也同样适用(请参阅子 Make 传递选项, 以及如何与 GNU 共享工作槽). GNU Make 使用了一种 jobserver 的方法(关于 jobserver 的详细介绍),控制递归调用中活动作业的数量。请注意,只有将 make 理解为 make 递归调用的命令行才能访问 jobserver(请参见 make 变量的运行方式)。在编写 makefile 时,必须确保将命令标记为递归,最常见的方法是在命令行前面加上 + 指示符(了解 make 的递归用法)。
如何运行?
过程很简单:
1.准备 Makefile,其中包括各种配方(材料),每个配方都可以作为单独进程运行(配方,就像做菜一样,很形象,我们决定保留这个名字?)
2.运行:make -j <number of jobs>
进行一个简单的演示。我们将使用 C++ 项目,希望大家能在这个演示中有所收获。在未来的世界,也许数字货币已经见怪不怪了,所以比特币的 C++ 代码将成为经典。共识机制问题的解决方法有很多,而且这些方法也许更省能源。因此,与大家因为投资比特币工作量证明(proof-of-work)耗费的能源相比,比特币对环境的负面影响就小多了。其他的方法也许能减少生成新区块或者扩展区块链所需的时间,权益证明和空间证明都是可以考虑在内。无论何时,我们都必须考虑货币分配在整个系统中的公平性,任何支持网络的人都应该得到奖励。这些重要的话题,我们将在未来继续讨论…
我们将使用 Bitcoin Core,之前 Wladimir van der Laan 设计的 Bitcoin-Qt,是以 Satoshi Nakamoto 的 C++ 源码为基础设置的。比特币网络中绝大多数完整节点都是运行 Bitcoin Core 代码。这个代码无疑占据了网络经济的半壁江山,成为执行协议规则的主导代码。
要在 MacOSX 上构建 Bitcoin Core(不使用 GUI 的情况下),需遵循以下步骤。其他平台的说明和配置,请点击链接。
复制存储库
复制存储库
git clone https://github.com/bitcoin/bitcoin.git
更改为比特币目录
cd bitcoin
设置依赖关系——需要使用 Berkeley数据库来支持旧的钱包地址
brew install berkeley-db@4
配置Makefile
./autogen.sh
./configure –without-bdb –with-gui=no
现在,一个 Makefile 已经创建好了,接下来准备编译,N 表示要执行的并行作业的数量(省略了一个 if 选项):
make -j N
请查看下表中单个作业的构建时间(以秒计):
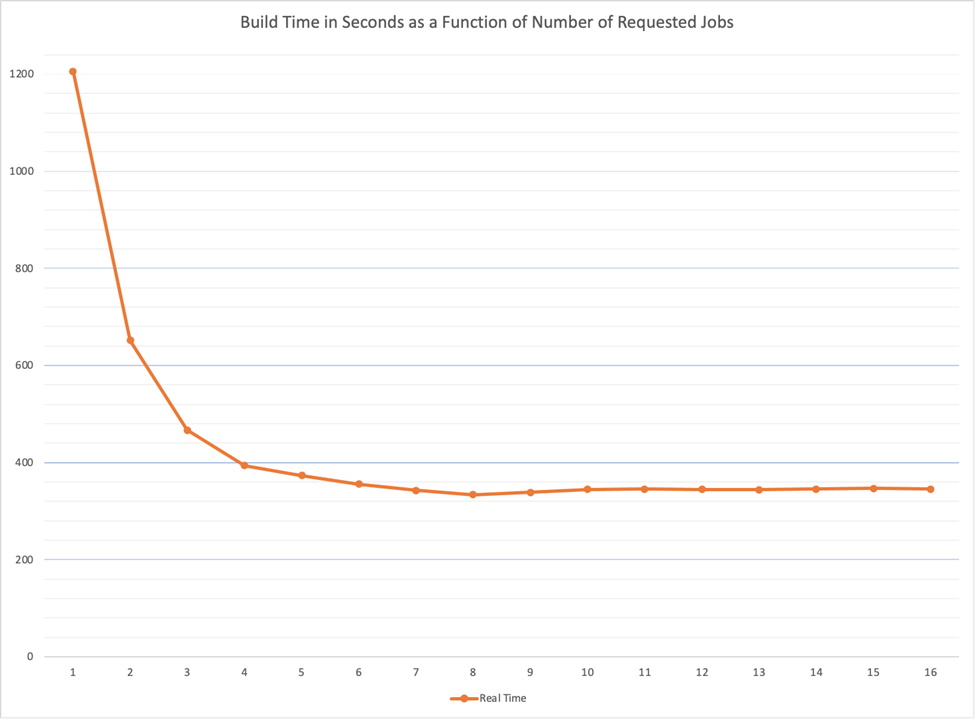
在 2.7 GHz 四核 Intel Core i7(超线程)机器上执行单个作业的平均构建时间数(以秒计)
由于这是一个超线程的四核机器,每个内核可以同时处理两个作业,因此我们有 8 个作业并行的潜力。在低负载的机器上,当我们将请求的作业数增加到 8 时,构建速度会更快,这很容易理解。然而,当要求 8 个以上的作业时,有一小部分内核需要超负荷运行,构建时间会增加。
我们还可以从这个实验中看到,当我们将作业数设置为内核数 4 时,构建时间显著缩短。并行处理 5-8 个作业时,效果肯定会更明显。但这些结果表明,超线程机器并不会使计算能力翻倍。
但是如果系统加载了怎么办?请记住,并行性也可以通过一个简单的“&”来实现,Ori Hoch 在博客《善用并行,让构建倍速进行》中解释得很详细。
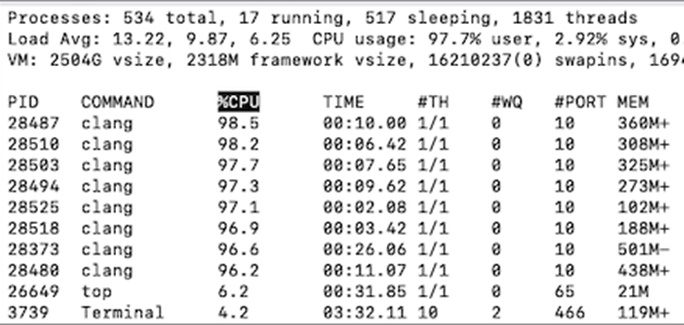
执行 8 个并行作业时的屏幕截图。
请注意屏幕截图中的 Load Avg数据,这是指在执行 8 个并行构建作业期间获取的值。此时的平均负载为 13.22,但显然不是 8 个作业并行运行的最佳时间。
另外,我们还可以使用下列标志:
-l 或者 –max-load
当系统负载较大时,我们需要减少作业数量。我们可以使用 -l 或 -max load 选项,根据平均负载设置并行的作业数量限制。该选项后面跟着一个小数点位。例如:make -j 8 -l 6.5 ,意思是当平均负载高于 6.5 个作业时,将限制 make 启动更多作业。更准确地说,make 在启动一个新作业之前,如果有一个作业正在运行,那么他将首先检查当前的平均负载。如果平均负载数高于 ‘-l ‘ 中的限制值,make 将等到负载低于该数值,或者其他作业完成时再启动新的作业(参见《GNU 用户手册-并行执行》)。
结论
我们已经了解到,并行构建是加速构建速度不可或缺的优秀工具。上面提到的 -j 选项能够显著加快构建时间。但这种加速有其限制,我们无法超越机器的性能,也无法利用除了机器自身内核之外的资源。
重新思考一下前面提到的案例:6 名工程师在等待构建结束时,不得不闲下来,浪费了宝贵的开发时间。但如果他们都坐下来喝喝茶聊聊天,同时把闲置的 CPU 利用起来,执行并行构建,故事又会怎样变化?
本地网络中难免会有闲置的内核资源,有时甚至还有空闲的超级计算机,拥有数百个没被利用的内核。此时此刻,如果出现一个构建系统,将这些空闲 CPU 收集起来,并分担并行构建的负载,效果会怎样呢?甚至,如果你可以在公共云中调用更多的计算资源呢?这就是分布式构建解决方案大展身手的地方,比如 Incredibuild 提供的高效解决方案。我们将在下一篇博客中讨论并行分布式构建。



